Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.

Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications You must be signed in to change notification settings
Papers from the computer science community to read and discuss.
papers-we-love/papers-we-love
Folders and files, repository files navigation.
Papers We Love ( PWL ) is a community built around reading, discussing and learning more about academic computer science papers. This repository serves as a directory of some of the best papers the community can find, bringing together documents scattered across the web. You can also visit the Papers We Love site for more info.
Due to licenses we cannot always host the papers themselves (when we do, you will see a 📜 emoji next to its title in the directory README) but we can provide links to their locations.
If you enjoy the papers, perhaps stop by a local chapter meetup and join in on the vibrant discussions around them. You can also discuss PWL events, the content in this repository, and/or anything related to PWL on our Discord server.
Let us know if you are interested in starting one in your city!
All of our meetups follow our Code of Conduct .
Past Presentations
Check out our YouTube channel for videos and video playlists.
We're looking for pull requests related to papers we should add, better organization of the papers we do have, and/or links to other paper-repos we should point to.
Other Good Places to Find Papers
- 2 Minute Papers
- Bell System Technical Journal, 1922-1983
- Best Paper Awards in Computer Science
- Google Scholar (choose a subcategory)
- Microsoft Research
- Functional Programming Books Review
- MIT's Artificial Intelligence Lab Publications
- MIT's Distributed System's Reading Group
- arXiv Paper Repository
- Services Engineering Reading List
- Readings in Distributed Systems
- Gradual Typing Bibliography
- Security Data Science Papers
- Research Papers from Robert Harper, Carnegie Mellon University
- Lobste.rs tagged as PDF
- The Morning Paper
- eugeneyan/applied-ml GitHub repository
Please check out our wiki-page for links to blogs, books, exchanges that are worth a good read.
How To Read a Paper
Reading a paper is not the same as reading a blogpost or a novel. Here are a few handy resources to help you get started.
- How to read an academic article
- Advice on reading academic papers
- How to read and understand a scientific paper
- Should I Read Papers?
- The Refreshingly Rewarding Realm of Research Papers
- How to read a paper
Applications/Ideas built around Papers We Love
- Love a Paper - @loveapaper
Download papers
Open your favourite terminal and run:
This will scrape markdown files for links to PDFs and download papers to their respective directories.
See README.md for more options.
Contributing Guidelines
Please take a look at our CONTRIBUTING.md file.
The name "Papers We Love" and the logos for the organization are copyrighted, and under the ownership of Papers We Love Ltd, all rights reserved. When starting a chapter, please review our guidelines and ask us about using the logo.
Code of conduct
Contributors 255.
- Shell 100.0%
computer science Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords
Hiring CS Graduates: What We Learned from Employers
Computer science ( CS ) majors are in high demand and account for a large part of national computer and information technology job market applicants. Employment in this sector is projected to grow 12% between 2018 and 2028, which is faster than the average of all other occupations. Published data are available on traditional non-computer science-specific hiring processes. However, the hiring process for CS majors may be different. It is critical to have up-to-date information on questions such as “what positions are in high demand for CS majors?,” “what is a typical hiring process?,” and “what do employers say they look for when hiring CS graduates?” This article discusses the analysis of a survey of 218 recruiters hiring CS graduates in the United States. We used Atlas.ti to analyze qualitative survey data and report the results on what positions are in the highest demand, the hiring process, and the resume review process. Our study revealed that a software developer was the most common job the recruiters were looking to fill. We found that the hiring process steps for CS graduates are generally aligned with traditional hiring steps, with an additional emphasis on technical and coding tests. Recruiters reported that their hiring choices were based on reviewing resume’s experience, GPA, and projects sections. The results provide insights into the hiring process, decision making, resume analysis, and some discrepancies between current undergraduate CS program outcomes and employers’ expectations.
A Systematic Literature Review of Empiricism and Norms of Reporting in Computing Education Research Literature
Context. Computing Education Research (CER) is critical to help the computing education community and policy makers support the increasing population of students who need to learn computing skills for future careers. For a community to systematically advance knowledge about a topic, the members must be able to understand published work thoroughly enough to perform replications, conduct meta-analyses, and build theories. There is a need to understand whether published research allows the CER community to systematically advance knowledge and build theories. Objectives. The goal of this study is to characterize the reporting of empiricism in Computing Education Research literature by identifying whether publications include content necessary for researchers to perform replications, meta-analyses, and theory building. We answer three research questions related to this goal: (RQ1) What percentage of papers in CER venues have some form of empirical evaluation? (RQ2) Of the papers that have empirical evaluation, what are the characteristics of the empirical evaluation? (RQ3) Of the papers that have empirical evaluation, do they follow norms (both for inclusion and for labeling of information needed for replication, meta-analysis, and, eventually, theory-building) for reporting empirical work? Methods. We conducted a systematic literature review of the 2014 and 2015 proceedings or issues of five CER venues: Technical Symposium on Computer Science Education (SIGCSE TS), International Symposium on Computing Education Research (ICER), Conference on Innovation and Technology in Computer Science Education (ITiCSE), ACM Transactions on Computing Education (TOCE), and Computer Science Education (CSE). We developed and applied the CER Empiricism Assessment Rubric to the 427 papers accepted and published at these venues over 2014 and 2015. Two people evaluated each paper using the Base Rubric for characterizing the paper. An individual person applied the other rubrics to characterize the norms of reporting, as appropriate for the paper type. Any discrepancies or questions were discussed between multiple reviewers to resolve. Results. We found that over 80% of papers accepted across all five venues had some form of empirical evaluation. Quantitative evaluation methods were the most frequently reported. Papers most frequently reported results on interventions around pedagogical techniques, curriculum, community, or tools. There was a split in papers that had some type of comparison between an intervention and some other dataset or baseline. Most papers reported related work, following the expectations for doing so in the SIGCSE and CER community. However, many papers were lacking properly reported research objectives, goals, research questions, or hypotheses; description of participants; study design; data collection; and threats to validity. These results align with prior surveys of the CER literature. Conclusions. CER authors are contributing empirical results to the literature; however, not all norms for reporting are met. We encourage authors to provide clear, labeled details about their work so readers can use the study methodologies and results for replications and meta-analyses. As our community grows, our reporting of CER should mature to help establish computing education theory to support the next generation of computing learners.
Light Diacritic Restoration to Disambiguate Homographs in Modern Arabic Texts
Diacritic restoration (also known as diacritization or vowelization) is the process of inserting the correct diacritical markings into a text. Modern Arabic is typically written without diacritics, e.g., newspapers. This lack of diacritical markings often causes ambiguity, and though natives are adept at resolving, there are times they may fail. Diacritic restoration is a classical problem in computer science. Still, as most of the works tackle the full (heavy) diacritization of text, we, however, are interested in diacritizing the text using a fewer number of diacritics. Studies have shown that a fully diacritized text is visually displeasing and slows down the reading. This article proposes a system to diacritize homographs using the least number of diacritics, thus the name “light.” There is a large class of words that fall under the homograph category, and we will be dealing with the class of words that share the spelling but not the meaning. With fewer diacritics, we do not expect any effect on reading speed, while eye strain is reduced. The system contains morphological analyzer and context similarities. The morphological analyzer is used to generate all word candidates for diacritics. Then, through a statistical approach and context similarities, we resolve the homographs. Experimentally, the system shows very promising results, and our best accuracy is 85.6%.
A genre-based analysis of questions and comments in Q&A sessions after conference paper presentations in computer science
Gender diversity in computer science at a large public r1 research university: reporting on a self-study.
With the number of jobs in computer occupations on the rise, there is a greater need for computer science (CS) graduates than ever. At the same time, most CS departments across the country are only seeing 25–30% of women students in their classes, meaning that we are failing to draw interest from a large portion of the population. In this work, we explore the gender gap in CS at Rutgers University–New Brunswick, a large public R1 research university, using three data sets that span thousands of students across six academic years. Specifically, we combine these data sets to study the gender gaps in four core CS courses and explore the correlation of several factors with retention and the impact of these factors on changes to the gender gap as students proceed through the CS courses toward completing the CS major. For example, we find that a significant percentage of women students taking the introductory CS1 course for majors do not intend to major in CS, which may be a contributing factor to a large increase in the gender gap immediately after CS1. This finding implies that part of the retention task is attracting these women students to further explore the major. Results from our study include both novel findings and findings that are consistent with known challenges for increasing gender diversity in CS. In both cases, we provide extensive quantitative data in support of the findings.
Designing for Student-Directedness: How K–12 Teachers Utilize Peers to Support Projects
Student-directed projects—projects in which students have individual control over what they create and how to create it—are a promising practice for supporting the development of conceptual understanding and personal interest in K–12 computer science classrooms. In this article, we explore a central (and perhaps counterintuitive) design principle identified by a group of K–12 computer science teachers who support student-directed projects in their classrooms: in order for students to develop their own ideas and determine how to pursue them, students must have opportunities to engage with other students’ work. In this qualitative study, we investigated the instructional practices of 25 K–12 teachers using a series of in-depth, semi-structured interviews to develop understandings of how they used peer work to support student-directed projects in their classrooms. Teachers described supporting their students in navigating three stages of project development: generating ideas, pursuing ideas, and presenting ideas. For each of these three stages, teachers considered multiple factors to encourage engagement with peer work in their classrooms, including the quality and completeness of shared work and the modes of interaction with the work. We discuss how this pedagogical approach offers students new relationships to their own learning, to their peers, and to their teachers and communicates important messages to students about their own competence and agency, potentially contributing to aims within computer science for broadening participation.
Creativity in CS1: A Literature Review
Computer science is a fast-growing field in today’s digitized age, and working in this industry often requires creativity and innovative thought. An issue within computer science education, however, is that large introductory programming courses often involve little opportunity for creative thinking within coursework. The undergraduate introductory programming course (CS1) is notorious for its poor student performance and retention rates across multiple institutions. Integrating opportunities for creative thinking may help combat this issue by adding a personal touch to course content, which could allow beginner CS students to better relate to the abstract world of programming. Research on the role of creativity in computer science education (CSE) is an interesting area with a lot of room for exploration due to the complexity of the phenomenon of creativity as well as the CSE research field being fairly new compared to some other education fields where this topic has been more closely explored. To contribute to this area of research, this article provides a literature review exploring the concept of creativity as relevant to computer science education and CS1 in particular. Based on the review of the literature, we conclude creativity is an essential component to computer science, and the type of creativity that computer science requires is in fact, a teachable skill through the use of various tools and strategies. These strategies include the integration of open-ended assignments, large collaborative projects, learning by teaching, multimedia projects, small creative computational exercises, game development projects, digitally produced art, robotics, digital story-telling, music manipulation, and project-based learning. Research on each of these strategies and their effects on student experiences within CS1 is discussed in this review. Last, six main components of creativity-enhancing activities are identified based on the studies about incorporating creativity into CS1. These components are as follows: Collaboration, Relevance, Autonomy, Ownership, Hands-On Learning, and Visual Feedback. The purpose of this article is to contribute to computer science educators’ understanding of how creativity is best understood in the context of computer science education and explore practical applications of creativity theory in CS1 classrooms. This is an important collection of information for restructuring aspects of future introductory programming courses in creative, innovative ways that benefit student learning.
CATS: Customizable Abstractive Topic-based Summarization
Neural sequence-to-sequence models are the state-of-the-art approach used in abstractive summarization of textual documents, useful for producing condensed versions of source text narratives without being restricted to using only words from the original text. Despite the advances in abstractive summarization, custom generation of summaries (e.g., towards a user’s preference) remains unexplored. In this article, we present CATS, an abstractive neural summarization model that summarizes content in a sequence-to-sequence fashion while also introducing a new mechanism to control the underlying latent topic distribution of the produced summaries. We empirically illustrate the efficacy of our model in producing customized summaries and present findings that facilitate the design of such systems. We use the well-known CNN/DailyMail dataset to evaluate our model. Furthermore, we present a transfer-learning method and demonstrate the effectiveness of our approach in a low resource setting, i.e., abstractive summarization of meetings minutes, where combining the main available meetings’ transcripts datasets, AMI and International Computer Science Institute(ICSI) , results in merely a few hundred training documents.
Exploring students’ and lecturers’ views on collaboration and cooperation in computer science courses - a qualitative analysis
Factors affecting student educational choices regarding oer material in computer science, export citation format, share document.
Help | Advanced Search
Computer Science (since January 1993)
For a specific paper , enter the identifier into the top right search box.
- new (most recent mailing, with abstracts)
- recent (last 5 mailings)
- current month's listings
- specific year/month: 2024 2023 2022 2021 2020 2019 2018 2017 2016 2015 2014 2013 2012 2011 2010 2009 2008 2007 2006 2005 2004 2003 2002 2001 2000 1999 1998 1997 1996 1995 1994 1993 all months 01 (Jan) 02 (Feb) 03 (Mar) 04 (Apr) 05 (May) 06 (Jun) 07 (Jul) 08 (Aug) 09 (Sep) 10 (Oct) 11 (Nov) 12 (Dec)
- Catch-up: Categories: All Artificial Intelligence Hardware Architecture Computational Complexity Computational Engineering, Finance, and Science Computational Geometry Computation and Language Cryptography and Security Computer Vision and Pattern Recognition Computers and Society Databases Distributed, Parallel, and Cluster Computing Digital Libraries Discrete Mathematics Data Structures and Algorithms Emerging Technologies Formal Languages and Automata Theory General Literature Graphics Computer Science and Game Theory Human-Computer Interaction Information Retrieval Information Theory Machine Learning Logic in Computer Science Multiagent Systems Multimedia Mathematical Software Numerical Analysis Neural and Evolutionary Computing Networking and Internet Architecture Other Computer Science Operating Systems Performance Programming Languages Robotics Symbolic Computation Sound Software Engineering Social and Information Networks Systems and Control Changes since: 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 01 (Jan) 02 (Feb) 03 (Mar) 04 (Apr) 05 (May) 06 (Jun) 07 (Jul) 08 (Aug) 09 (Sep) 10 (Oct) 11 (Nov) 12 (Dec) 2024 2023 , view results without with abstracts
- Search within the cs archive
- Article statistics by year: 2024 2023 2022 2021 2020 2019 2018 2017 2016 2015 2014 2013 2012 2011 2010 2009 2008 2007 2006 2005 2004 2003 2002 2001 2000 1999 1998 1997 1996 1995 1994 1993
Categories within Computer Science
- cs.AI - Artificial Intelligence ( new , recent , current month ) Covers all areas of AI except Vision, Robotics, Machine Learning, Multiagent Systems, and Computation and Language (Natural Language Processing), which have separate subject areas. In particular, includes Expert Systems, Theorem Proving (although this may overlap with Logic in Computer Science), Knowledge Representation, Planning, and Uncertainty in AI. Roughly includes material in ACM Subject Classes I.2.0, I.2.1, I.2.3, I.2.4, I.2.8, and I.2.11.
- cs.AR - Hardware Architecture ( new , recent , current month ) Covers systems organization and hardware architecture. Roughly includes material in ACM Subject Classes C.0, C.1, and C.5.
- cs.CC - Computational Complexity ( new , recent , current month ) Covers models of computation, complexity classes, structural complexity, complexity tradeoffs, upper and lower bounds. Roughly includes material in ACM Subject Classes F.1 (computation by abstract devices), F.2.3 (tradeoffs among complexity measures), and F.4.3 (formal languages), although some material in formal languages may be more appropriate for Logic in Computer Science. Some material in F.2.1 and F.2.2, may also be appropriate here, but is more likely to have Data Structures and Algorithms as the primary subject area.
- cs.CE - Computational Engineering, Finance, and Science ( new , recent , current month ) Covers applications of computer science to the mathematical modeling of complex systems in the fields of science, engineering, and finance. Papers here are interdisciplinary and applications-oriented, focusing on techniques and tools that enable challenging computational simulations to be performed, for which the use of supercomputers or distributed computing platforms is often required. Includes material in ACM Subject Classes J.2, J.3, and J.4 (economics).
- cs.CG - Computational Geometry ( new , recent , current month ) Roughly includes material in ACM Subject Classes I.3.5 and F.2.2.
- cs.CL - Computation and Language ( new , recent , current month ) Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.
- cs.CR - Cryptography and Security ( new , recent , current month ) Covers all areas of cryptography and security including authentication, public key cryptosytems, proof-carrying code, etc. Roughly includes material in ACM Subject Classes D.4.6 and E.3.
- cs.CV - Computer Vision and Pattern Recognition ( new , recent , current month ) Covers image processing, computer vision, pattern recognition, and scene understanding. Roughly includes material in ACM Subject Classes I.2.10, I.4, and I.5.
- cs.CY - Computers and Society ( new , recent , current month ) Covers impact of computers on society, computer ethics, information technology and public policy, legal aspects of computing, computers and education. Roughly includes material in ACM Subject Classes K.0, K.2, K.3, K.4, K.5, and K.7.
- cs.DB - Databases ( new , recent , current month ) Covers database management, datamining, and data processing. Roughly includes material in ACM Subject Classes E.2, E.5, H.0, H.2, and J.1.
- cs.DC - Distributed, Parallel, and Cluster Computing ( new , recent , current month ) Covers fault-tolerance, distributed algorithms, stabilility, parallel computation, and cluster computing. Roughly includes material in ACM Subject Classes C.1.2, C.1.4, C.2.4, D.1.3, D.4.5, D.4.7, E.1.
- cs.DL - Digital Libraries ( new , recent , current month ) Covers all aspects of the digital library design and document and text creation. Note that there will be some overlap with Information Retrieval (which is a separate subject area). Roughly includes material in ACM Subject Classes H.3.5, H.3.6, H.3.7, I.7.
- cs.DM - Discrete Mathematics ( new , recent , current month ) Covers combinatorics, graph theory, applications of probability. Roughly includes material in ACM Subject Classes G.2 and G.3.
- cs.DS - Data Structures and Algorithms ( new , recent , current month ) Covers data structures and analysis of algorithms. Roughly includes material in ACM Subject Classes E.1, E.2, F.2.1, and F.2.2.
- cs.ET - Emerging Technologies ( new , recent , current month ) Covers approaches to information processing (computing, communication, sensing) and bio-chemical analysis based on alternatives to silicon CMOS-based technologies, such as nanoscale electronic, photonic, spin-based, superconducting, mechanical, bio-chemical and quantum technologies (this list is not exclusive). Topics of interest include (1) building blocks for emerging technologies, their scalability and adoption in larger systems, including integration with traditional technologies, (2) modeling, design and optimization of novel devices and systems, (3) models of computation, algorithm design and programming for emerging technologies.
- cs.FL - Formal Languages and Automata Theory ( new , recent , current month ) Covers automata theory, formal language theory, grammars, and combinatorics on words. This roughly corresponds to ACM Subject Classes F.1.1, and F.4.3. Papers dealing with computational complexity should go to cs.CC; papers dealing with logic should go to cs.LO.
- cs.GL - General Literature ( new , recent , current month ) Covers introductory material, survey material, predictions of future trends, biographies, and miscellaneous computer-science related material. Roughly includes all of ACM Subject Class A, except it does not include conference proceedings (which will be listed in the appropriate subject area).
- cs.GR - Graphics ( new , recent , current month ) Covers all aspects of computer graphics. Roughly includes material in all of ACM Subject Class I.3, except that I.3.5 is is likely to have Computational Geometry as the primary subject area.
- cs.GT - Computer Science and Game Theory ( new , recent , current month ) Covers all theoretical and applied aspects at the intersection of computer science and game theory, including work in mechanism design, learning in games (which may overlap with Learning), foundations of agent modeling in games (which may overlap with Multiagent systems), coordination, specification and formal methods for non-cooperative computational environments. The area also deals with applications of game theory to areas such as electronic commerce.
- cs.HC - Human-Computer Interaction ( new , recent , current month ) Covers human factors, user interfaces, and collaborative computing. Roughly includes material in ACM Subject Classes H.1.2 and all of H.5, except for H.5.1, which is more likely to have Multimedia as the primary subject area.
- cs.IR - Information Retrieval ( new , recent , current month ) Covers indexing, dictionaries, retrieval, content and analysis. Roughly includes material in ACM Subject Classes H.3.0, H.3.1, H.3.2, H.3.3, and H.3.4.
- cs.IT - Information Theory ( new , recent , current month ) Covers theoretical and experimental aspects of information theory and coding. Includes material in ACM Subject Class E.4 and intersects with H.1.1.
- cs.LG - Machine Learning ( new , recent , current month ) Papers on all aspects of machine learning research (supervised, unsupervised, reinforcement learning, bandit problems, and so on) including also robustness, explanation, fairness, and methodology. cs.LG is also an appropriate primary category for applications of machine learning methods.
- cs.LO - Logic in Computer Science ( new , recent , current month ) Covers all aspects of logic in computer science, including finite model theory, logics of programs, modal logic, and program verification. Programming language semantics should have Programming Languages as the primary subject area. Roughly includes material in ACM Subject Classes D.2.4, F.3.1, F.4.0, F.4.1, and F.4.2; some material in F.4.3 (formal languages) may also be appropriate here, although Computational Complexity is typically the more appropriate subject area.
- cs.MA - Multiagent Systems ( new , recent , current month ) Covers multiagent systems, distributed artificial intelligence, intelligent agents, coordinated interactions. and practical applications. Roughly covers ACM Subject Class I.2.11.
- cs.MM - Multimedia ( new , recent , current month ) Roughly includes material in ACM Subject Class H.5.1.
- cs.MS - Mathematical Software ( new , recent , current month ) Roughly includes material in ACM Subject Class G.4.
- cs.NA - Numerical Analysis ( new , recent , current month ) cs.NA is an alias for math.NA. Roughly includes material in ACM Subject Class G.1.
- cs.NE - Neural and Evolutionary Computing ( new , recent , current month ) Covers neural networks, connectionism, genetic algorithms, artificial life, adaptive behavior. Roughly includes some material in ACM Subject Class C.1.3, I.2.6, I.5.
- cs.NI - Networking and Internet Architecture ( new , recent , current month ) Covers all aspects of computer communication networks, including network architecture and design, network protocols, and internetwork standards (like TCP/IP). Also includes topics, such as web caching, that are directly relevant to Internet architecture and performance. Roughly includes all of ACM Subject Class C.2 except C.2.4, which is more likely to have Distributed, Parallel, and Cluster Computing as the primary subject area.
- cs.OH - Other Computer Science ( new , recent , current month ) This is the classification to use for documents that do not fit anywhere else.
- cs.OS - Operating Systems ( new , recent , current month ) Roughly includes material in ACM Subject Classes D.4.1, D.4.2., D.4.3, D.4.4, D.4.5, D.4.7, and D.4.9.
- cs.PF - Performance ( new , recent , current month ) Covers performance measurement and evaluation, queueing, and simulation. Roughly includes material in ACM Subject Classes D.4.8 and K.6.2.
- cs.PL - Programming Languages ( new , recent , current month ) Covers programming language semantics, language features, programming approaches (such as object-oriented programming, functional programming, logic programming). Also includes material on compilers oriented towards programming languages; other material on compilers may be more appropriate in Architecture (AR). Roughly includes material in ACM Subject Classes D.1 and D.3.
- cs.RO - Robotics ( new , recent , current month ) Roughly includes material in ACM Subject Class I.2.9.
- cs.SC - Symbolic Computation ( new , recent , current month ) Roughly includes material in ACM Subject Class I.1.
- cs.SD - Sound ( new , recent , current month ) Covers all aspects of computing with sound, and sound as an information channel. Includes models of sound, analysis and synthesis, audio user interfaces, sonification of data, computer music, and sound signal processing. Includes ACM Subject Class H.5.5, and intersects with H.1.2, H.5.1, H.5.2, I.2.7, I.5.4, I.6.3, J.5, K.4.2.
- cs.SE - Software Engineering ( new , recent , current month ) Covers design tools, software metrics, testing and debugging, programming environments, etc. Roughly includes material in all of ACM Subject Classes D.2, except that D.2.4 (program verification) should probably have Logics in Computer Science as the primary subject area.
- cs.SI - Social and Information Networks ( new , recent , current month ) Covers the design, analysis, and modeling of social and information networks, including their applications for on-line information access, communication, and interaction, and their roles as datasets in the exploration of questions in these and other domains, including connections to the social and biological sciences. Analysis and modeling of such networks includes topics in ACM Subject classes F.2, G.2, G.3, H.2, and I.2; applications in computing include topics in H.3, H.4, and H.5; and applications at the interface of computing and other disciplines include topics in J.1--J.7. Papers on computer communication systems and network protocols (e.g. TCP/IP) are generally a closer fit to the Networking and Internet Architecture (cs.NI) category.
- cs.SY - Systems and Control ( new , recent , current month ) cs.SY is an alias for eess.SY. This section includes theoretical and experimental research covering all facets of automatic control systems. The section is focused on methods of control system analysis and design using tools of modeling, simulation and optimization. Specific areas of research include nonlinear, distributed, adaptive, stochastic and robust control in addition to hybrid and discrete event systems. Application areas include automotive and aerospace control systems, network control, biological systems, multiagent and cooperative control, robotics, reinforcement learning, sensor networks, control of cyber-physical and energy-related systems, and control of computing systems.
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
Computer science articles from across Nature Portfolio
Computer science is the study and development of the protocols required for automated processing and manipulation of data. This includes, for example, creating algorithms for efficiently searching large volumes of information or encrypting data so that it can be stored and transmitted securely.

Creating sound bubbles with intelligent headsets
A combination of artificial intelligence and noise-cancelling technology can be used to create headsets with customizable auditory zones — or sound bubbles — that allow users to focus on sounds within a designated area while suppressing sounds outside of it.
Latest Research and Reviews

Enhancing advanced cervical cell categorization with cluster-based intelligent systems by a novel integrated CNN approach with skip mechanisms and GAN-based augmentation
- Gunjan Shandilya
- Sheifali Gupta
- Seada Hussen

Generative learning assisted state-of-health estimation for sustainable battery recycling with random retirement conditions
Data scarcity and heterogeneity impede the estimation of retired battery capacity. Here, Tao et al. propose a generative learning method that extends measured data space, potentially reducing curation time, cost and facilitating their sustainable reuse and recycling.
- Shengyu Tao
- Guangmin Zhou

Multiple strategies improved spider wasp optimization for engineering optimization problem solving
- Zuoxun Wang

Training ESRGAN with multi-scale attention U-Net discriminator

Dual-task vision transformer for rapid and accurate intracerebral hemorrhage CT image classification
- Jialiang Fan

Actual usage assessment among cloud storage consumers in the Philippines using a machine learning ensemble approach
- Ardvin Kester S. Ong
- Gerlyn C. Altes
- Josephine D. German
News and Comment

What Trump’s election win could mean for AI, climate and health
Donald Trump made numerous promises during his presidential campaign that could affect scientists and science policy. Will they be implemented once he is president?
- Jeff Tollefson
- Traci Watson

ChatGPT is transforming peer review — how can we use it responsibly?
At major computer-science publication venues, up to 17% of the peer reviews are now written by artificial intelligence. We need guidelines before things get out of hand.

AI watermarking must be watertight to be effective
Scientists are closing in on a tool that can reliably identify AI-generated text without affecting the user’s experience. But the technology’s robustness remains a challenge.
Build an international AI ‘telescope’ to curb the power of big tech companies
- Pierre Baldi
- Piero Fariselli
- Giorgio Parisi

How I peer into the geometry behind computer vision
Minh Ha Quang’s work at a Japanese AI research centre aims to understand how machines extract image data from the real world.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies

You should be reading academic computer science papers
You read documentation and tutorials to become a better programmer, but if you really want to be cutting-edge, academic research is where it's at.

[Ed. note: While we take some time to rest up over the holidays and prepare for next year, we are re-publishing our top ten posts for the year. This is our number one post of 2022! Thanks for reading and we’ll see you in the new year. ]
As working programmers, you need to keep learning all the time. You check out tutorials, documentation, Stack Overflow questions, anything you can find that will help you write code and keep your skills current. But how often do you find yourself digging into academic computer science papers to improve your programming chops?
While the tutorials can help you write code right now, it’s the academic papers that can help you understand where programming came from and where it’s going. Every programming feature, from the null pointer (aka the billion dollar mistake ) to objects (via Smalltalk ) has been built on a foundation of research that stretches back to the 1960s (and earlier). Future innovations will be built on the research of today.
We spoke to three of the members of the Papers We Love team, an online repository of their favorite computer science scholarship.
Zeeshan Lakhani, an engineering director at BlockFi, Darren Newton, an engineering team lead at Datadog, and David Ashby, a staff engineer at SageSure, all met while working at a company called Arc90. They found that none of them had formal training in computer science, but they all wanted to learn more. All three came from humanities and arts disciplines: Ashby has an English degree with a history minor, Newton went to art school twice, and Lakhani went to film school for undergrad before getting a master’s degree in music and audio engineering. All of those fields of study rely heavily on reading texts that built the foundation of the discipline as to understand the theory that underlies all practice.
Like any good student of the humanities, they went looking for answers in the archives. “I had a latent librarian inside,” said Newton. “So I'm always interested in the historical source material for the things that I do.”
Surveying history
As part of learning more about the history of programming, Ashby was reading Tracy Kidder’s Soul of a New Machine , about the race to design a 32-bit microcomputer in the late 70s. It covered both the engineering culture at the time and the problems and concepts those engineers wrestled with. This was before the time of mass-market CPUs and standard motherboard components, so a lot of what we take for granted today was still being worked out.
In Kidder’s book, Lakhani, Newton, and Ashby saw a whole history of computer science that they had no connection with, so they decided to try reading a foundational paper: Tony Hoare ’s “ Communicating Sequential Processes ” from 1978. They were working on Clojure and Clojurescript at the time, so this seemed relevant. When they sat down to discuss the paper, they realized they didn’t even know how to approach understanding it. “It was like, I can't understand half of this formalism, but maybe the intro is pretty good,” said Lakhani. “But we need someone like David Nolen to explain this to us.”
Nolen was an acquaintance who worked for The New York Times . He gave a talk there about Clojure and other Lisp-like languages, referencing a lot of John McCarthy’s early papers. Hearing this explanation with the academic context started turning a few gears in their minds. That’s when the idea of Papers We Love was born.
Knowing the history of the computing concepts that you use every day unlocks a lot of understanding into how they work at a practical level. The tools that you use, from databases to programming languages, are built on a foundation of academic research. “Understanding the roots of the things you're working on unlocks a lot of knowledge that you're not going to get purely just by using every day because you don't understand the paths that they didn't go down,” said Ashby.
There’s a talk they love that Bret Victor gave in 2013 called “ The Future of Programming .” He’s dressed like an engineer from the 70s, white button-up, khakis, pocket protector. He starts giving his talk using an overhead projector that has the name of the talk. He adjusts the slide and it reveals that the date is 1973. He goes on to talk about all the great things coming out of research, all the things that are going to shake up computer science. And they’re all things that the audience is still dealing with, like the move from sequential execution to concurrent models.
“The top theme was that it takes a long time,” said Lakhani. “There's a lot of things that are old that are new again, over and over and over.” The same problems are still relevant, whether because the problems are harder than once thought or because the research into those problems has been widely shared.
The trio behind Papers We Love aren’t alone in discovering a love for computing’s history. There is an increased interest in retrocomputing , engineers looking at the systems of the past to learn more about the practice of technology. It’s the flipside of looking at older papers; you look at the old hardware and software programmers used and work on it with a present-day mindset. “A lot of people are spinning up these ancient operating systems on Raspberry PIs and working with them,” said Newton. “Like spinning up an old Smalltalk VM on a Raspberry PI or recreating a PDP-10.”
When you see these issues in their initial contexts, like reading the research papers that tried to address them, you can get a better perspective on where you are now. That can lead to all sorts of epiphanies. “Oh, objects do the things they do because of Smalltalk back in the 80s,” said Ashby. “And that's why big systems look like that. And that's why Java looks like that.”
That new understanding can help you solve the problems that you face now.
The future of programming (today)
There’s more to reading research papers than understanding history; you can find new ways to solve problems by reading current research. “The idea of Stack Overflow is: someone else has had your problem before,” said Ashby. “Academic papers are: someone else has thought about this problem before.”
If your work involves building variations of the same old CRUD app in new spaces, then maybe research papers won’t help you. But if you are trying to solve the unique problems of your industry, then some of the research in those problem spaces may help you overcome them. “I find papers to expand the idea of what's possible with the work you do,” said Ashby. “They can help you appreciate that there are other ways to solve these problems.”
For Newton and his colleagues at Datadog, academic papers are an integral part of their work. Their monitoring software has to process a lot of information in real time to give engineers a view of their applications and the stack they run on. “We are very concerned with performance algorithms and better ways to do statistics on large volumes of data ,” said Newton. “We need to rely on academic research for some of that.”
Just because research exists, of course, it doesn’t mean your problems are automatically solved. Sometimes a single paper only gets you part of the solution. “I was at Comcast where we wanted to leverage load balancing work that we do in terms of routing,” said Lakhani. “We ended up applying three different kinds of papers that didn't know each other. We put semantics into network packets, routed them based on another paper via a specific protocol, and implemented a bunch of IETF specs. Part of this work now lives in a Rust library people can run today.” It's finding threads in academic work and braiding them together to solve the problems at hand.
Without reading those papers, Lakhani’s team wouldn’t have been able to design such an effective solution. Perhaps they would have gotten there on their own. But imagine the amount of work to research those three concepts; there’s no need to redo their work if it’s already been done. It’s standing on the shoulders of giants, as the saying goes, and if you’re on top of the research in your field, you know exactly which giants to stand on.
A map of the giants’ shoulders
Naturally, being a graduate of the humanities myself, I wanted to know which were the giants of computer science, those papers that would be on the syllabus if you were to construct a humanities-style curricula for a class. Think of it as a map of which giant shoulders you could stand on to get ahead.
It turns out, I’m not the first to wonder what’s in the computer science canon. In 1996, Phillip Laplante wrote Great Papers in Computer Science , which might be a bit outdated at this point. For a more recent take on the same thing, the trio recommend Ideas That Created the Future , published last year. Lakhani, who is now doing a PhD in computer science at Carnegie Mellon University (my alma mater), points out that there was a course when he arrived that covered the important papers of the field.
In a way, this canon is exactly what the Papers We Love repo aims to create. It contains papers and links to papers organized by topic. The group welcomes new pull requests with academic papers that you all love and want to see spotlighted.
Here are a few papers (and talks) that they recommended to anyone wanting to get started reading the research:
- Dynamo: Amazon’s Highly Available Key-value Store
- A Unified Theory of Garbage Collection
- Communicating Sequential Processes
- Out of the Tar Pit
Of course, there are many more.
If you’re intimidated by starting on a paper, then check out some of Papers We Love’s presentations , which offer a primer on how to understand a paper. The whole idea of these talks is borne out of that first frustration with a paper, then finding a path through it with someone else’s help. “They've gotten the CliffsNotes,” says Lakhani. “Now they can attack the paper and really understand it.”
The Papers We Love community continues to try to build a bridge between industry and academia. Everyone benefits—the industry gets access to new solutions without having to wait for someone else to implement and open-source them, and academics get to see their ideas tested and implemented in real situations.
“One of the goals of Papers We Love is to make it where you find out about stuff a little bit faster,” said Lakhani. “Maybe that changes things.”
Add to the discussion
Mendeley Blog
The top 10 research papers in computer science by mendeley readership..
Since we recently announced our $10001 Binary Battle to promote applications built on the Mendeley API ( now including PLoS as well), I decided to take a look at the data to see what people have to work with. My analysis focused on our second largest discipline, Computer Science. Biological Sciences (my discipline) is the largest, but I started with this one so that I could look at the data with fresh eyes, and also because it’s got some really cool papers to talk about. Here’s what I found: What I found was a fascinating list of topics, with many of the expected fundamental papers like Shannon’s Theory of Information and the Google paper, a strong showing from Mapreduce and machine learning, but also some interesting hints that augmented reality may be becoming more of an actual reality soon.

LDA is a means of classifying objects, such as documents, based on their underlying topics. I was surprised to see this paper as number one instead of Shannon’s information theory paper (#7) or the paper describing the concept that became Google (#3). It turns out that interest in this paper is very strong among those who list artificial intelligence as their subdiscipline. In fact, AI researchers contributed the majority of readership to 6 out of the top 10 papers. Presumably, those interested in popular topics such as machine learning list themselves under AI, which explains the strength of this subdiscipline, whereas papers like the Mapreduce one or the Google paper appeal to a broad range of subdisciplines, giving those papers a smaller numbers spread across more subdisciplines. Professor Blei is also a bit of a superstar, so that didn’t hurt. (the irony of a manually-categorized list with an LDA paper at the top has not escaped us)
2. MapReduce : Simplified Data Processing on Large Clusters (available full-text)

It’s no surprise to see this in the Top 10 either, given the huge appeal of this parallelization technique for breaking down huge computations into easily executable and recombinable chunks. The importance of the monolithic “Big Iron” supercomputer has been on the wane for decades. The interesting thing about this paper is that had some of the lowest readership scores of the top papers within a subdiscipline, but folks from across the entire spectrum of computer science are reading it. This is perhaps expected for such a general purpose technique, but given the above it’s strange that there are no AI readers of this paper at all.
3. The Anatomy of a large-scale hypertextual search engine (available full-text)

In this paper, Google founders Sergey Brin and Larry Page discuss how Google was created and how it initially worked. This is another paper that has high readership across a broad swath of disciplines, including AI, but wasn’t dominated by any one discipline. I would expect that the largest share of readers have it in their library mostly out of curiosity rather than direct relevance to their research. It’s a fascinating piece of history related to something that has now become part of our every day lives.
4. Distinctive Image Features from Scale-Invariant Keypoints

This paper was new to me, although I’m sure it’s not new to many of you. This paper describes how to identify objects in a video stream without regard to how near or far away they are or how they’re oriented with respect to the camera. AI again drove the popularity of this paper in large part and to understand why, think “ Augmented Reality “. AR is the futuristic idea most familiar to the average sci-fi enthusiast as Terminator-vision . Given the strong interest in the topic, AR could be closer than we think, but we’ll probably use it to layer Groupon deals over shops we pass by instead of building unstoppable fighting machines.
5. Reinforcement Learning: An Introduction (available full-text)

This is another machine learning paper and its presence in the top 10 is primarily due to AI, with a small contribution from folks listing neural networks as their discipline, most likely due to the paper being published in IEEE Transactions on Neural Networks. Reinforcement learning is essentially a technique that borrows from biology, where the behavior of an intelligent agent is is controlled by the amount of positive stimuli, or reinforcement, it receives in an environment where there are many different interacting positive and negative stimuli. This is how we’ll teach the robots behaviors in a human fashion, before they rise up and destroy us.
6. Toward the next generation of recommender systems: a survey of the state-of-the-art and possible extensions (available full-text)

Popular among AI and information retrieval researchers, this paper discusses recommendation algorithms and classifies them into collaborative, content-based, or hybrid. While I wouldn’t call this paper a groundbreaking event of the caliber of the Shannon paper above, I can certainly understand why it makes such a strong showing here. If you’re using Mendeley, you’re using both collaborative and content-based discovery methods!
7. A Mathematical Theory of Communication (available full-text)

Now we’re back to more fundamental papers. I would really have expected this to be at least number 3 or 4, but the strong showing by the AI discipline for the machine learning papers in spots 1, 4, and 5 pushed it down. This paper discusses the theory of sending communications down a noisy channel and demonstrates a few key engineering parameters, such as entropy, which is the range of states of a given communication. It’s one of the more fundamental papers of computer science, founding the field of information theory and enabling the development of the very tubes through which you received this web page you’re reading now. It’s also the first place the word “bit”, short for binary digit, is found in the published literature.
8. The Semantic Web (available full-text)

In The Semantic Web, Tim Berners-Lee, Sir Tim, the inventor of the World Wide Web, describes his vision for the web of the future. Now, 10 years later, it’s fascinating to look back though it and see on which points the web has delivered on its promise and how far away we still remain in so many others. This is different from the other papers above in that it’s a descriptive piece, not primary research as above, but still deserves it’s place in the list and readership will only grow as we get ever closer to his vision.
9. Convex Optimization (available full-text)

This is a very popular book on a widely used optimization technique in signal processing. Convex optimization tries to find the provably optimal solution to an optimization problem, as opposed to a nearby maximum or minimum. While this seems like a highly specialized niche area, it’s of importance to machine learning and AI researchers, so it was able to pull in a nice readership on Mendeley. Professor Boyd has a very popular set of video classes at Stanford on the subject, which probably gave this a little boost, as well. The point here is that print publications aren’t the only way of communicating your ideas. Videos of techniques at SciVee or JoVE or recorded lectures ( previously ) can really help spread awareness of your research.
10. Object recognition from local scale-invariant features (available in full-text)

This is another paper on the same topic as paper #4, and it’s by the same author. Looking across subdisciplines as we did here, it’s not surprising to see two related papers, of interest to the main driving discipline, appear twice. Adding the readers from this paper to the #4 paper would be enough to put it in the #2 spot, just below the LDA paper.
Conclusions
So what’s the moral of the story? Well, there are a few things to note. First of all, it shows that Mendeley readership data is good enough to reveal both papers of long-standing importance as well as interesting upcoming trends. Fun stuff can be done with this! How about a Mendeley leaderboard? You could grab the number of readers for each paper published by members of your group, and have some friendly competition to see who can get the most readers, month-over-month. Comparing yourself against others in terms of readers per paper could put a big smile on your face, or it could be a gentle nudge to get out to more conferences or maybe record a video of your technique for JoVE or Khan Academy or just Youtube.
Another thing to note is that these results don’t necessarily mean that AI researchers are the most influential researchers or the most numerous, just the best at being accounted for. To make sure you’re counted properly, be sure you list your subdiscipline on your profile, or if you can’t find your exact one, pick the closest one, like the machine learning folks did with the AI subdiscipline. We recognize that almost everyone does interdisciplinary work these days. We’re working on a more flexible discipline assignment system, but for now, just pick your favorite one.
These stats were derived from the entire readership history, so they do reflect a founder effect to some degree. Limiting the analysis to the past 3 months would probably reveal different trends and comparing month-to-month changes could reveal rising stars.
Technical details: To do this analysis I queried the Mendeley database, analyzed the data using R , and prepared the figures with Tableau Public . A similar analysis can be done dynamically using the Mendeley API . The API returns JSON, which can be imported into R using the fine RJSONIO package from Duncan Temple Lang and Carl Boettiger is implementing the Mendeley API in R . You could also interface with the Google Visualization API to make motion charts showing a dynamic representation of this multi-dimensional data. There’s all kinds of stuff you could do, so go have some fun with it. I know I did.
Share this:
2 thoughts on “ the top 10 research papers in computer science by mendeley readership. ”.
You might consider revisiting the subdiscipline list, e.g. split computer vision, robotics and machine learning from AI, since the latest is a fuzzy and uncertain concept. Neural networks could be combined with machine learning, though.
Especially in fast-growing fields like computer science, discipline will always be a somewhat fuzzy concept. We are working on a way for people to assign themselves and papers to disciplines in a more flexible way.
Comments are closed.

- Already have a WordPress.com account? Log in now.
- Subscribe Subscribed
- Copy shortlink
- Report this content
- View post in Reader
- Manage subscriptions
- Collapse this bar
Reference management. Clean and simple.
The top list of computer science research databases

1. ACM Digital Library
2. ieee xplore digital library, 3. dblp computer science bibliography, 4. springer lecture notes in computer science (lncs), frequently asked questions about computer science research databases, related articles.
Besides the interdisciplinary research databases Web of Science and Scopus there are also academic databases specifically dedicated to computer science. We have compiled a list of the top 4 research databases with a special focus on computer science to help you find research papers, scholarly articles, and conference papers fast.
ACM Digital Library is the clear number one when it comes to academic databases for computer science. The ACM Full-Text Collection currently has 540,000+ articles, while the ACM Guide to Computing Literature holds more than 2.8+ million bibliographic entries.
- Coverage: 2.8+ million articles
- Abstracts: ✔
- Related articles: ✘
- References: ✔
- Cited by: ✔
- Full text: ✔ (requires institutional subscription)
- Export formats: BibTeX, EndNote

Pro tip: Use a reference manager like Paperpile to keep track of all your sources. Paperpile integrates with ACM Digital Library and many popular databases, so you can save references and PDFs directly to your library using the Paperpile buttons and later cite them in thousands of citation styles:
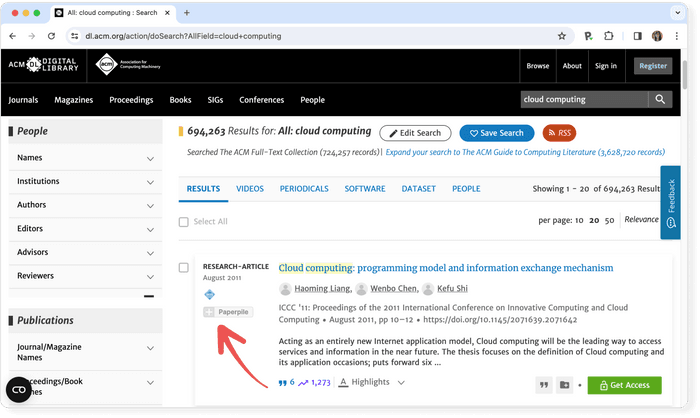
IEEE Xplore holds more than 4.7 million research articles from the fields of electrical engineering, computer science, and electronics. It not only covers articles published in scholarly journals, but also conference papers, technical standards, as well as some books.
- Coverage: 4.7+ million articles
- Export formats: BibTeX, RIS

Hosted at the University of Trier, Germany, dbpl has become an indispensable resource in the field of computer science. Its index covers journal articles, conference and workshop proceedings, as well as monographs.
- Coverage: 4.3 million articles
- Abstracts: ✘
- References: ✘
- Cited by: ✘
- Full text: ✘ (Links to publisher websites available)
- Export formats: RIS, BibTeX

Springer's Lecture Notes in Computer Science is the number one publishing source for conference proceedings covering all areas of computer science.
- Coverage: 415,000+ articles
- Export formats: RIS, EndNote, BibTeX

Hosted at the University of Trier, Germany, dbpl has become an indispensable resource in the field of computer science. It's index covers journal articles, conference and workshop proceedings, as well as monographs.
Microsoft Academic was a free academic search engine developed by Microsoft Research. It had more than 13.9 million articles indexed. It was shut down in 2022.
EEE Xplore holds more than 4.7 million research articles from the fields of electrical engineering, computer science, and electronics. It not only covers articles published in scholarly journals, but also conference papers, technical standards, as well as some books.

IMAGES
VIDEO
COMMENTS
Papers We Love (PWL) is a community built around reading, discussing and learning more about academic computer science papers. This repository serves as a directory of some of the best papers the community can find, bringing together documents scattered across the web. You can also visit the Papers We Love site for more info.
Computer science ( CS ) majors are in high demand and account for a large part of national computer and information technology job market applicants. Employment in this sector is projected to grow 12% between 2018 and 2028, which is faster than the average of all other occupations. Published data are available on traditional non-computer ...
cs.CY - Computers and Society (new, recent, current month) Covers impact of computers on society, computer ethics, information technology and public policy, legal aspects of computing, computers and education. Roughly includes material in ACM Subject Classes K.0, K.2, K.3, K.4, K.5, and K.7.
We also believe that highlighting excellent research will inspire others to enter the computing education field and make their own contributions.". The Top Ten Symposium Papers are: 1. " Identifying student misconceptions of programming " (2010) Lisa C. Kaczmarczyk, Elizabeth R. Petrick, University of California, San Diego; Philip East ...
Computer science is the study and development of the protocols required for automated processing and manipulation of data. This includes, for example, creating algorithms for efficiently searching ...
Explore the latest full-text research PDFs, articles, conference papers, preprints and more on COMPUTER SCIENCE. Find methods information, sources, references or conduct a literature review on ...
The future of programming (today) There's more to reading research papers than understanding history; you can find new ways to solve problems by reading current research. "The idea of Stack Overflow is: someone else has had your problem before," said Ashby. "Academic papers are: someone else has thought about this problem before.".
Every once in a while, one finds a paper so astounding (e.g., important, compelling, deceptively simple, etc.) that one wants to share it with everyone. So list these papers here! They don't have to be from theoretical computer science -- anything that you think might appeal to the community is a fine answer.
1. Latent Dirichlet Allocation (available full-text) LDA is a means of classifying objects, such as documents, based on their underlying topics. I was surprised to see this paper as number one instead of Shannon's information theory paper (#7) or the paper describing the concept that became Google (#3).
Get 30 days free. 1. ACM Digital Library. ACM Digital Library is the clear number one when it comes to academic databases for computer science. The ACM Full-Text Collection currently has 540,000+ articles, while the ACM Guide to Computing Literature holds more than 2.8+ million bibliographic entries. Coverage: 2.8+ million articles. Abstracts: .